目次
前説
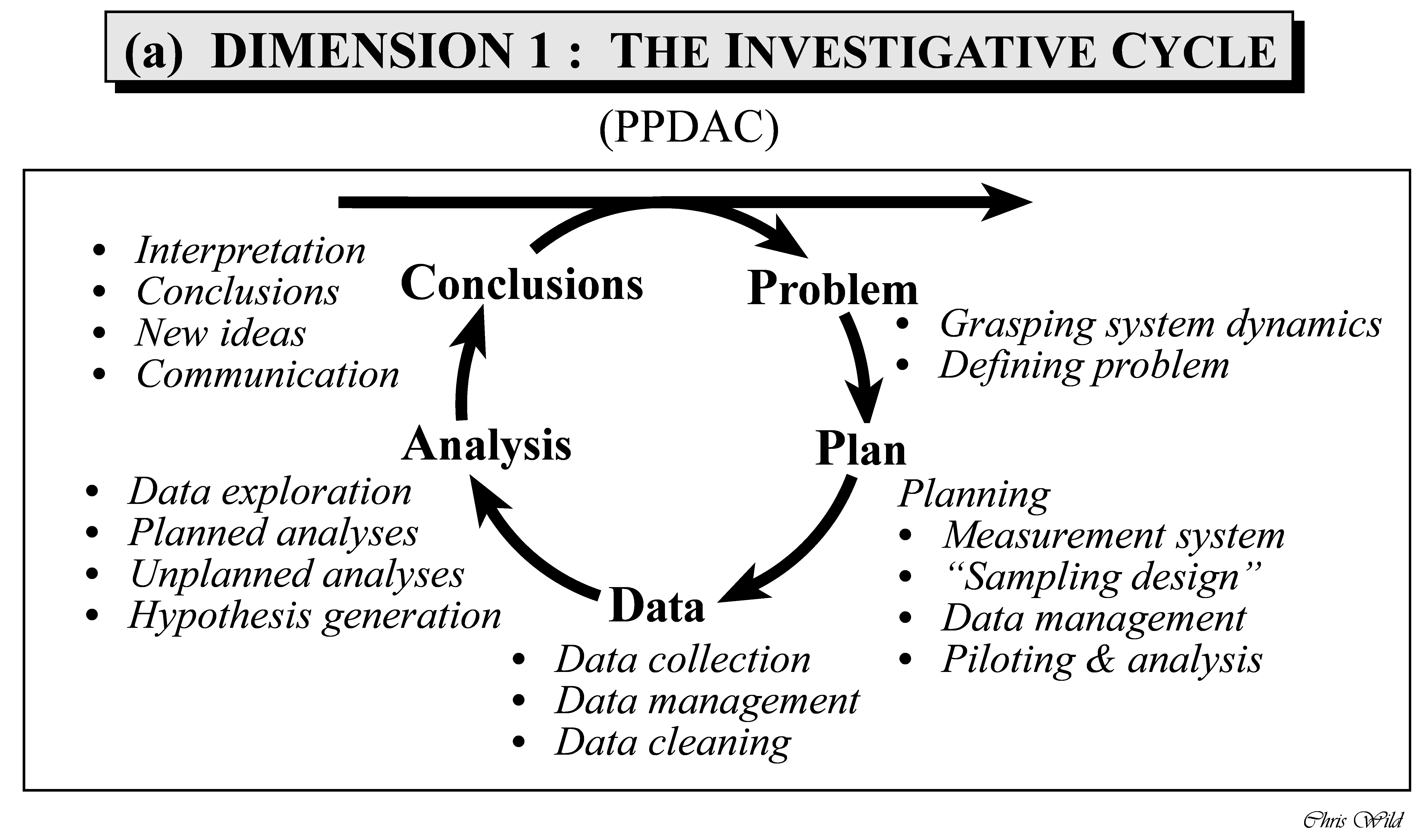
PPDAC
対象の事実を観察して、疑問や問題を明確にしてから、データをに基づいて疑問や問題の解決を図ることは、科学的探索の基本姿勢である。 そのための取り組みの流れの一つに、PPDACサイクルがある。Problem, Plan, Data, Analysis, Conclusionの5つのステップからなる問題解決への取り組みをPPDACと呼ぶ。この取り組みは、PからCまで素直に到達できることを保証する訳ではない。Problem, Planと進み、Dataステップで適切なデータが入手できないことが判明して、またPlanをやりなおす、などもあり得る。
表:PPDAC
| Step | ステップ | 図 | |
| P | Problem | 問題設定 |  |
| P | Plan | 計画 | |
| D | Data | データ | |
| A | Analysis | 解析 | |
| C | Conclusion | 結論 |
PPDACサイクルはこの5つのステップを繰り返すことで、真実に近づいていく。逆にこれらがないとどうなるか。Problemステップで設定する問題と目的なしには、Planステップで目標が検討しにくい。またPlanステップで設定する目標なしには、Dataステップでのデータ収集とAnalysisステップでの解析プロセスが迷子になり、またAnalysisステップを終えてConclusionステップに移るタイミングを判断できない。 前のステップをしっかりと進めた方が、次のステップが順調に進みやすい、という点でQCストーリーと似ている。
PPDACの図は、Googleさんに聞いてから画像検索を依頼すれば、たくさん表示されるので、一つ、一番古いと思われるものを引用した。これは、このページに掲載されているカナダ発のこの図で、これ以外にもたくさんの図がインターネット上には見つかる。
{kind=link}
データの解析には、問題の明確化と目的の設定(P:Problem)、次いで、目的の設定を受けた目標の設定(P:Plan)が不可欠だからである。どのような問題を解決・解消するために、あるいは、どのような状況を改善するためにデータを扱うか、をまず明確にする。そして、その問題や状況の現状をデータから定量的に把握する。そのために問題を明確にして、分析の目的を設定しなければ、解析の手順が容易に迷子になりうる。ヒストグラムや棒グラフを描くにせよ、クロス集計したり散布図などを描くにせよ、どの変数あるいはどの集計値(統計量とも)を基準に考え、あるいはどのような評価尺度を改善していくか、をまず明確にするのである。
目的(P:Problem)はデータの解析が目指す方向を示し、目標(P:Plan)はどんな解析結果を得ると結論(C:Conclusion)を得られるかを示す。 目的と目標とが決まれば、あとはどのようなデータ(D:Data)を収集して、どのように分析(A:Analysis)すればよいかのアプローチが定まる。 分析には、層別しながらとなるが、集計やグラフなどの手作業、回帰分析などの多変量解析手法、決定木やクラスタリングなどのデータマイニング手法、サポートベクトルマシンや弱機械のブースティングなどの機械学習の手法などを用いる。求めているのは目標を達成するような分析結果であり、様々な手法はそのための手段に過ぎないことは常に認識しておく必要がある。
このような考えの進め方にPPDACが適しているので、この実験はこれに基づいて設計した。他にも科学的探求の方法、と呼ばれるアプローチ(サイクル、取り組み方、進め方、ステップなど)は様々あるので、興味のある人は調べてみるといい。
本題
ここからは、今週の実験手順の説明。実験はペアで行ってもらいます。最初の週に隣同士に座った2人ずつ。
- パソコンは1人1台使ってください。
- 作業は1人のパソコンでやっても、2人で同時にやっても構いませんが、相談しながらやってください。
- 作業内容は分担しても、同時に同じことをやりながら進めても構いませんが、相談しながらやってください。
- 帰るときには、ペアで同じ状態(同じプログラム、同じグラフ、同じ表)を持ち帰ってください。
- レポートは一人1通としてください。
- すべての作業は自宅でもRをインストールすれば行えますので、帰宅後に追加作業を行っても構いません。それ以降の結果をレポート作成時に共有するか否かはお任せします。でも次の週には共有してください。
- 考察は相談しても一人ずつでも構いません。
最低限の準備
ここからEZRのインストーラをダウンロードしてインストールするか、あるいはインストール済みのRにEZRを追加インストールするか、を選んでください。以下は、後者の場合の手順。
- このページに目を通すこと。データの読み込み手順も記述してある。
- 必要に応じて、追加パッケージもインストールしてみる。例えば
Sys.setenv("http_proxy"="http://130.153.8.19:8080/") install.packages(c("Rcmdr", "RcmdrPlugin.EZR"), dependencies = TRUE)を実行してから
library(Rcmdr)
を実行すると、EZR入りのRコマンダーが起動される。
最初のステップ
データを分析・解析・マイニング・サイエンスする、あらゆる場合に、データに触れる前に、おおよその中身についての思いを巡らす。データの全体像を大まかに入れる箱を、まずは頭の中に用意する、とも言える。心の準備とも言えるが、この段階をきちんと経ないと、ビジョンやイメージを持てなくて、容易に迷子になる。
その次は、パートナーとこれだけの情報から出発して、ネットを使って情報を収集しながら、このデータについての情報を膨らましつつ、このExcelファイルの中の問いに答えながら、データ解析のためのPPDACの最初のPと2つめのPを進める。ここでの作業は「ブレーンストーミング」とその結果の体系化、なので、相手のいうことを批判してはだめ。
ここでは、
- 親和図法の結果としての図が1枚。
- 連関図法の結果としての図が1枚。
の合わせて2枚の図が成果物となる。
続いてRの入門
こちらをさらっと眺めておくといい。
ここまでが準備
実際の実験取り組み
事前解析としての変数の理解
保険会社の顧客データを用いる。このデータの背景と概要については、リンク先のページを参照のこと。
ここでの成果物は、変数の分類表、あるいは特性要因図、あるいは親和図と連関図の2つ、のいずれか。データを解析する前に、変数一覧を眺めて検討することが大事。
問題の確認 (PPDACのPとP)
今年はデータに触れる前に、まずは実験のペア同士で保険会社の顧客データのページを眺めながら、このデータについてディスカッションすること。ディスカッションの目的は次の2つ。
- 86個ある変数について、思いついたことをメモ書きし、状況を整理し、その分類を考えること。(親和図法)
- 86個ある変数のうち、V86とある「CARAVAN」と関係のありそうな変数を事前に検討しておくこと。(連関図法)
新QC7つ道具のうち、親和図法と連関図法について、少し学ぶ。
現状の把握 (PPDACのD)
まずはデータの変数一覧を眺めて相談しながら、V86とどの変数が関係ありそうか、どの変数が関係なさそうか、をExcelなどに変数表をコピーして、表を作って整理する。
例えば、こんな表。
| 関係ありそう | どちらとも言えない | 関係なさそう | |
| 変数 | V1-V10 | V53 | V22 |
あるいは、特性要因図を作ってもいい。魚の頭がV86。
QC7つ道具 (手法の説明のみ)
前置きが長くなったが、今回はQC7つ道具の幾つかを用いて、データを解析してもらう。 QC7つ道具とは、
- パレート図: 問題の優先順位の決定 (1次元の分析法)
- グラフ: データの図示
- 管理図: 対象の安定性の検討
- チェックシート: データの取得と現状の図示
- ヒストグラム: 分布の検討
- 散布図: 因果関係の分析
- 層別: 問題の細分化、切り分け、掘り下げ
- 特性要因図: メカニズムや因果関係の検討
の8種類の手法・道具のセットである。データから事実を把握するための手法および問題を解析するための手法の集まりとして、5学期開講の品質管理でも紹介されている。そしてQCストーリーとの対応関係
- テーマの選定: 問題を絞る
- 現状把握: QC7つ道具の出番
- 解析: QC7つ道具の出番
- 対策: 解析に基づいて対策を講じる
- 効果の確認: 再現性の確認
- 標準化: 他への展開
- 残された課題と今後の進め方: 解決に満足せずに次のPDCAに繋げる
から、現状把握と解析でQC7つ道具を精力的に用いることになる。
EZR(Rコマンダー)を用いたデータの要約
ここでの成果物は、ヒストグラム、箱ひげ図、分割表(クロス集計)、散布図など。
Rコマンダーを使うなら、下記のURLがとても参考になる。
これらを斜め読みすれば使い始めることができる簡単なソフトウェアで、今回はグラフと統計量のみを用いて、データの現状を把握し、定期預金の契約率の高いターゲット層を発見することが目標である。
- まずはRコマンダー入門など、上のリンク先にざっと目を通しながら、Rコマンダーに慣れる。
- bank.zipからCSVファイルを取り出して、Rコマンダーで読み込み、「統計量」と「グラフ」のみを用いて現状把握と解析を行う。目的がテレマーケティングによる定期預金の獲得であることは忘れない方がいい。またターゲット層の探索には「層別」を用いるが、種類がbinaryかcategoricalな変数でしか、層別ができないことに注意する。
- 今回の成果物として要求したいのは、次のもの。
- 5822人分のデータの概要を表す表やグラフ、その考察。
- 5822人分のデータから見つけた「Caravan Insuranceを契約しやすい層」と、その層に営業をかける時の成功率、そしてその層に至った経緯。ターゲット層とは、例えば「結婚していなくて、各種ローンがなくて、破産の経験もなければ、定期預金の契約率が少し高い」などのこと。
- 契約率は分割表から計算できる。
| 作業 | 参考 |
| Rコマンダーを起動する | Rコマンダー入門 第1節(p.1) |
| Rコマンダーでデータを読み込む | Rコマンダー入門 第2節(p.10) |
| 数値による要約 | Rコマンダー入門 第3節(p.15) |
RかRコマンダーを用いて行うこと
- 連関図法の結果のデータからの確認。
- ヒストグラム(hist())や1次元の集計(table())による、各変数の分布の検討
- 散布図(plot())、クロス集計(table())、箱ヒゲ図(boxplot())をうまく使い分けると、変数間の関係を検討できる
- データを分析しながら連関図法の改訂
データマイニング (ここから先は今週は手がけるだけ、次週に本格的に使う)
データ解析の手法は、ただ闇雲に用いただけで必要な知識がデータから抽出できるというものではない。様々な手法の、原理、仮定 (前提)、その手法が用いるモデルの構造とパラメータの意味を知り、それぞれの長所と短所を理解した上で 、解析するデータに適切な手法を用いるべきである。そのためには様々な手法を適用する前にまず、データそれ自体の理解が不可欠である。前回はこれを目的として、解析の第一段階としてのデータの理解に努めてもらった。
リンク先の同志社大学の金 (じん) 先生が公開してくださっているコンテンツを参考に、判別分析と決定木 (樹木モデル、分類木とも) を用いて、今回のデータを解析して貰う。解析の目的は「定期預金を契約する人と契約しない人の間に、どのような差異があるか」を調べることである。
保険会社の顧客データの解析
どのような特徴のあるデータかを把握できたら、次に、まず下記のページを順に読み、手順や内容などを理解せよ。(いずれも同志社大学の金先生が公開されているもの)
そこに書かれている操作などを実行してみると、実行画面と同じ結果が大きく表示される。表示される数字の読み方なども上のリンク先を参考にせよ。
そしてこれらの手法を先週と同じデータに適用して、定期預金を契約する顧客と契約しない顧客の間にどのような差異があるか、データ解析せよ。必要に応じて
も参考にせよ。ここでデータ解析とは、
- データの全体の概要の俯瞰 (前回の結果を用いてもよい)
- データの構造を捉えるようなモデルの当てはめ (下記のようにできる)
- モデルがデータによくあてはまっていることの確認と不確実性の評価 (表示できるグラフや、信頼区間などにより検討)
- 当てはめたモデルの考察 (得たモデルからの目的に関する検討)
などを行うことを指している
実行するだけなら
Sys.setenv("http_proxy"="http://130.153.8.16:8080/")
tic.learn <- read.table("http://kdd.ics.uci.edu/databases/tic/ticdata2000.txt")
install.packages(c("MASS", "rpart"), dependencies=TRUE)
library(MASS)
library(rpart)
lda(V86~., data=tic.learn)
qda(V86~., data=tic.learn)
rpart(V86~., data=tic.learn)
だけだが。。。? 上のコードでinstall.packages()がエラーになるときは、プロキシの設定が必要かもしれない。
課題
データ解析に基づいて、セールスの方針を提案せよ。
追加メモ
関数の出力の保存と参照
各関数(コマンド、分析プログラム、分析ツール、分析手法)を実行した結果を、オブジェクトとして保存できる。
v86.lda <- lda(V86~., data=tic.learn) v86.qda <- lda(V86~., data=tic.learn) v86.rpart <- rpart(V86~., data=tic.learn)
結果を表示するには、単にオブジェクト名を入力するか、もしくはprint関数に表示してもらう。
v86.lda print(v86.lda)
上の二行は同じ内容が表示されるので、どちらかでよい。
summary関数をかませると、追加の要約情報が表示されることがある。
summary(v86.lda)
これははずれ。上の三つの解析で必要な表示は、たとえば次のとおり。
print(v86.lda) print(v86.qda) print(v86.rpart) summary(v86.rpart)
グラフ描画
plot関数がそれぞれの関数ごとに、結果を表すグラフを描いてくれる、ことがある。
plot(v86.lda) plot(v86.qda) plot(v86.rpart)
決定木に関するグラフは、plot関数のみでは完結しない。plot関数は樹形の絵を描いてくれるだけで、分割の情報をtext関数に補わせて初めて、決定木、という図を得る。
plot(v86.rpart) text(v86.rpart)
文字が大きすぎるときは、グラフを描く前に文字の倍率を変えるように指示する。
par(cex=0.7) plot(v86.rpart) text(v86.rpart) par(cex=1.0)
個人的には、グラフ描画が終わったら倍率を1.0に戻すようにしている。
またリンク先を参考に、plot関数にオプションを追加すると、見た目が変わる。
par(cex=0.7) plot(v86.rpart,uniform=T,branch=0.6,margin=0.05) text(v86.rpart) par(cex=1.0)
rpart.plot:rpartのためのグラフ描画用のパッケージ
さらに次のパッケージとコマンドを使うと、もっと綺麗な図を描いてくれる。
install.packages(c("rpart.plot"), dependencies=TRUE)
library(rpart.plot)
prp(v86.rpart, type=2, extra=2)
typeとextraはいくつか選べるようである。
tree:もうひとつの決定木分析のためのパッケージ
ところでリンク先には、treeという関数も紹介されている。これを利用するには、同名のパッケージのインストールと読み込みが必要となる。
install.packages(c("tree"), dependencies=TRUE)
library(tree)
tree(V86~., data=tic.learn)
v86.tree <- tree(V86~., data=tic.learn)
plot(v86.tree)
text(v86.tree)
レポートについて
- 先週の親和図法と連関図法の結果をエクセルで作成して、ワードファイルに「横」にして貼り付け、解説すること。
- 特に連関図法の結果について、RかRコマンダーで検討すること。それら作成したグラフや表、また計算した集計値(統計値)などをレポートに含める場合、説明・報告・考察に必要なもののみを含めること。
- 図表は読みやすいように配置すること。