文書の過去の版を表示しています。
+目次
確率論
このページへの短縮URLはhttp://bit.ly/ymmtprob2012(山本確率2012の略記)。
お知らせ
- 2012.04.12は溢れたので、講義はせずに、ガイダンスに留めました。
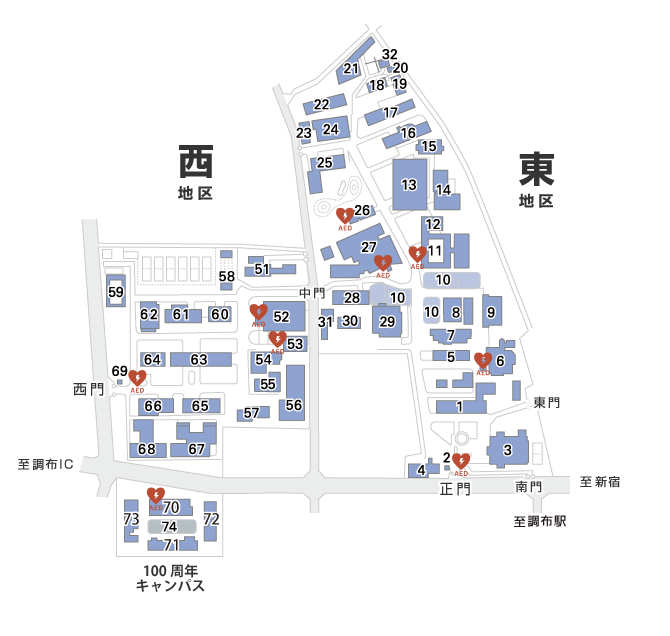
- 2012.04.19は西9号館1階の135という教室を使います。キャンパスマップの69番です。今日の出席率に基づいて、教室をどこにするか決定します。
- 2012.04.19以降、教室を西9-135に変更しました。
{kind=link}
担当
- 教員:山本
- TA:横山(鈴木研院生)
参考書
- 「確率・統計解析の基礎」, 久保木久孝・著, 朝倉書店
- 「統計学のための数学入門30講」, 永田靖・著, 朝倉書店
- 「統計技法」, 宮川雅巳・著, 共立出版
授業計画
| 回 | テーマ | トピック | 予定日 | 実施日 | レポート課題 |
|---|---|---|---|---|---|
| #01 | ガイダンス、確率の基礎概念(1) | 事象,確率 | 2012.04.12 | なし。 | |
| #02 | 確率の基礎概念(2) | 事象,確率 | 2012.04.19 | ||
| #03 | 確率の基礎概念(3) | 条件つき確率と独立性,ベイズの定理 | 2012.04.26 | ||
| #04 | 確率変数と分布関数(1) | 確率変数,確率分布,分布関数 | 2012.05.10 | ||
| #05 | 確率変数と分布関数(2) | 確率変数のモーメント,分散 | 2012.05.17 | ||
| #06 | モーメント母関数とその応用(1),離散型確率モデル(1) | モーメント母艦数,ベルヌーイ分布,二項分布 | 2012.05.24 | ||
| #07 | 離散型確率モデル(2),連続型確率モデル(1) | 幾何分布,負の二項分布,ポアソン分布,指数分布 | 2012.05.31 | ||
| #08 | 連続型確率モデル(1) | ポアソン分布と指数分布の関係,正規分布 | 2012.06.07 | ||
| #09 | 中間試験および解説 | 2012.06.14 | |||
| #09 | 確率ベクトルと分布関数(1) | 確率ベクトル,同時分布,周辺分布 | 2012.06.21 | ||
| #10 | 確率ベクトルと分布関数(2) | 確率変数の独立性,同時モーメント,共分散,相関係数 | 2012.06.28 | ||
| #11 | モーメント母関数とその応用(2) | 2012.07.05 | |||
| #12 | 連続型確率モデル(3) | 2変量正規分布 | 2012.07.12 | ||
| #13 | 大数の法則 | 2012.07.19 | |||
| #14 | 中心極限定理 | 2012.07.26 | |||
| #15 | 標本分布論 | 2012.08.02 | あ、ここ休講だ | ||
| #16 | 期末試験 | 試験期間中 |
この講義に関する負担
去年の反省を踏まえて、明確にします。
- 来週以降、試験の週を除いて毎週、課題を課します。(木曜出題→月曜昼休み提出→木曜返却、のサイクル)
- 中間試験と期末試験を行います。
- 出席はとりません。
- 成績評価は、課題と試験を総合して、学習の到達目標に達成しているかどうかの評価を行います。(課題ができていて、試験が少しできていなければ、救ってあげますが、課題ができていて、試験がぜんぜんだめなら、到達目標を達成しているとみなせないので・・・)
メモ
#01 2012.04.12
教室が溢れて授業ができませんでした。 各人各様に月曜2限を履修できない事情があるようなので、教室の変更の検討を教務課に依頼しました。
- 「喫煙は、さまざまながんの原因の中で、予防可能な最大の原因です。日本の研究では、がんの死亡のうち、男性で40%、女性で5%は喫煙が原因だと考えられています。特に肺がんは喫煙との関連が強く、肺がんの死亡のうち、男性で70%、女性で20%は喫煙が原因だと考えられています。」(喫煙とがんより)
- 「喫煙は、がんだけでなく、冠動脈心疾患(狭心症、心筋梗塞など)や脳卒中など循環器の病気、肺炎や慢性閉塞性(へいそくせい)肺疾患(COPD)など呼吸器の病気の原因でもあります。」
- 「慢性閉塞性肺疾患が起こる最大の原因は喫煙ですが、この病気になるのはタバコを吸う人の約15.20%にすぎません。」(http://www.koide-s.co.jp/heisoku.html
- 「喫煙者でタバコに感受性があると考えられる COPD 患者(約 15%)では、健康成 人の 3 倍、1 年間あたり約 60mL 以上のペースで肺機能が低下していくため、中高年を迎え るころには、息切れなどの臨床症状によって日常生活に支障をきたし、やがては HOT(在宅酸素療法 )、 そして最終的には死亡に至る。喫煙者の残り 85%は、非喫煙者と感受性のある者との間に正規分布するという。」喫煙と呼吸器疾患より)
- 競馬の払い戻し (JRAホームページ お問い合わせより)
- 「Q. 競馬の控除率は25%と言われますが、どうして25%になるのですか? A. 競馬の控除率は25%と言われますが、払戻金の算式を見ればわかるように売上総額から一律に25%を控除しているわけではありません。実際の控除率は、理論上18%~26.2%の間の値をとり、そのレースの不的中分が多ければ高くなり、少なければ低くなるというように変化します。 また、的中が多いレース=本命サイドで決着したレースでは控除率は低くなり、的中が少ないレース=大穴が出たレースでは控除率が高くなりますが、これらの控除率を平均すると、約25%になるので「控除率は25%」と言われているのです 。」JRAホームページ お問い合わせ
([[http://www.soumu.go.jp/main_content/000084191.pdf|宝くじ・公営競技・サッカーくじの実効還元率]]より) 還元率 競馬: 競艇: |競輪|払い戻し 75%, 施行自治体の収益(開催経費を含む) 20.6%, 金融公庫への納付金 1.1%, 日本自転車振興会への交付金(自転車等機械工業振興補助事業 1.6%, 体育・社会福祉等公益事業振興補助事業 1.4%, 競技の公正かつ円滑な実施を図るための事業 0.3%) 3.3% ([[http://www.city.takamatsu.kagawa.jp/file/2962_L11_keirinshikumi1.pdf|競輪のしくみ]]より)| 70%にする案が検討中 |宝くじ|当選金 46.2%, 印刷経費・売りさばき手数料など 14.7%, 都道府県及び20指定都市へ納付 39.1% [[http://www.takarakuji-official.jp/educate/about/proceeds/index.html|宝くじについて 収益金の使い道|宝くじ公式サイト]]より)| パチンコ・パチスロ:
#02 2012.04.19
試しに教室を大きくしてみることにしました。空いている教室が、B棟の階段教室と、西9-135しかありませんでしたので、 今週は、東地区のA101ではなく、西地区の一番奥の「西九号館」という建物の1階の135という教室を使います。 恐縮ですが、東(の一番手前のA棟)から西(の一番奥の西9号館)まで5分ほどかかります。
- 確率変数を定義した、らしい。
#03 2012.04.26
- 標本空間と確率変数と部分集合族の例と復習
- サイコロを念頭に、加法族、確率の公理、加法法則、条件付き確率、乗法法則、の説明まで。
- 第3回課題を配布した。
#04 2012.04.26
- 第4回課題を配布した。
- 加法法則、乗法法則、条件付き確率の公式
- ベイズの定理(標本空間を制限したときの条件付き確率の計算方法)
- 前回の課題の解説
- 離散集合と連続集合
- 標本空間が離散集合の場合の事象は点の集合で定義され、標本空間が連続集合の場合の事象は区間で定義される
- 分布関数の定義: <jsm>F\left(a,b\right)=Pr\left[X\in\left[a,b\right)\right]</jsm> と2変数関数として確率を定めるよりは <jsm>F\left(b\right)=Pr\left[X\in\left(-\infty,b\right)\right]</jsm> と1変数関数で定義するのがいい。区間確率は <jsm>Pr\left[X\in \left[a,b\right)\right] = F\left(b\right)-F\left(a\right)</jsm> と計算できるから。
分布関数は定義しただけなので、確率の公理を満たす確認は次回。そして、半端なところで終わったので、課題として配布したのは、次回に改めて課すつもりで、今回は無し。
#05 2012.05.10
#06 2012.05.17
#07 2012.05.24
- 前回の講義を補足するノートと課題を配布した。(最終更新 02:22pm)
以下は、今回のノートの図を作成するための、R言語のコード。
## source("prob-6-figures.r.txt") will produce the following EPS files.
# exponential-distribution-1.eps
# binomial-distribution-20-0.3-mean-stddev.eps
# exponential-distribution-1-mean-stddev.eps
# binomial-distribution-0.3.eps
# binomial-distribution-0.5.eps
# binomial-distribution-0.7.eps
# binomial-distribution-20-0.3.eps
# binomial-distribution-20-0.5.eps
# binomial-distribution-20-0.7.eps
# binomial-distribution-2-0.3.eps
# binomial-distribution-2-0.5.eps
# binomial-distribution-2-0.7.eps
# exponential-distribution.eps
## Binomial distribution
plot.binom <- function( size, prob, col="black", epsilon=0, connection=FALSE, cumulative.prob=FALSE) {
probs <- NULL
cprobs <- NULL
for( k in c(0:size) ) {
lines(c(k,k)+epsilon, c(0,dbinom(k, size=size, prob=prob)), type="l", col=col)
probs <- append(probs, dbinom(k, size=size, prob=prob))
cprobs <- append(cprobs, pbinom(k, size=size, prob=prob))
}
if( connection==TRUE ) {
lines(c(0:size)+epsilon, probs, type="b", col=col)
}
if( cumulative.prob==TRUE ) {
lines(c(0:size)+epsilon, cprobs, type="b", col=col)
}
}
## Mean and standard error
lines.binom.12 <- function(size, prob, delta=0, epsilon=0, lty=1, lwd=1, col="black", ylim=c(0,1)) {
lines( c(size*prob, size*prob), c(ylim[1]+delta, ylim[2]-delta), lty=lty, lwd=lwd, col=col)
lines( c(size*prob-sqrt(size*prob*(1-prob)), size*prob+sqrt(size*prob*(1-prob))),
c(mean(ylim), mean(ylim)), lty=lty, lwd=lwd, col=col)
}
# prob=0.5, n=c(1,3,5,10,20)
postscript("binomial-distribution-0.5.eps", width=8, height=4)
plot(c(0,20), c(0,0.7), type="n", xlab="k", ylab="probability", sub="prob=0.5")
plot.binom( size=1, prob=0.5, col="black", epsilon=0.0, connection=TRUE )
plot.binom( size=3, prob=0.5, col="red", epsilon=0.1, connection=TRUE )
plot.binom( size=5, prob=0.5, col="green", epsilon=0.2, connection=TRUE )
plot.binom( size=10, prob=0.5, col="blue", epsilon=0.3, connection=TRUE )
plot.binom( size=20, prob=0.5, col="blue", epsilon=0.4, connection=TRUE )
legend(12, 0.6, lty=1, col=c("black","red","green","blue","purple"),
legend=c("size=1","size=3","size=5","size=10","size=20"))
lines.binom.12( size=1, prob=0.5, ylim=c(0, 0.7), delta=0.1, col="blue", lwd=2, lty=3)
lines.binom.12( size=3, prob=0.5, ylim=c(0-0.01, 0.7-0.01), delta=0.1, col="red", lwd=2, lty=3)
lines.binom.12( size=5, prob=0.5, ylim=c(0-0.02, 0.7-0.02), delta=0.1, col="green", lwd=2, lty=3)
lines.binom.12( size=10, prob=0.5, ylim=c(0-0.03, 0.7-0.03), delta=0.1, col="blue", lwd=2, lty=3)
lines.binom.12( size=20, prob=0.5, ylim=c(0-0.04, 0.7-0.04), delta=0.1, col="purple", lwd=2, lty=3)
dev.off()
# prob=0.3, n=c(1,3,5,10,20)
postscript("binomial-distribution-0.3.eps", width=8, height=4)
plot(c(0,20), c(0,0.7), type="n", xlab="k", ylab="probability", sub="prob=0.3")
plot.binom( size=1, prob=0.3, col="black", epsilon=0.0, connection=TRUE )
plot.binom( size=3, prob=0.3, col="red", epsilon=0.1, connection=TRUE )
plot.binom( size=5, prob=0.3, col="green", epsilon=0.2, connection=TRUE )
plot.binom( size=10, prob=0.3, col="blue", epsilon=0.3, connection=TRUE )
plot.binom( size=20, prob=0.3, col="purple", epsilon=0.4, connection=TRUE )
legend(12, 0.6, lty=1, col=c("black","red","green","blue","purple"),
legend=c("size=1","size=3","size=5","size=10","size=20"))
lines.binom.12( size=1, prob=0.3, ylim=c(0, 0.7), delta=0.1, col="blue", lwd=2, lty=3)
lines.binom.12( size=3, prob=0.3, ylim=c(0-0.01, 0.7-0.01), delta=0.1, col="red", lwd=2, lty=3)
lines.binom.12( size=5, prob=0.3, ylim=c(0-0.02, 0.7-0.02), delta=0.1, col="green", lwd=2, lty=3)
lines.binom.12( size=10, prob=0.3, ylim=c(0-0.03, 0.7-0.03), delta=0.1, col="blue", lwd=2, lty=3)
lines.binom.12( size=20, prob=0.3, ylim=c(0-0.04, 0.7-0.04), delta=0.1, col="purple", lwd=2, lty=3)
dev.off()
# prob=0.7, n=c(1,3,5,10,20)
postscript("binomial-distribution-0.7.eps", width=8, height=4)
plot(c(0,20), c(0,0.7), type="n", xlab="k", ylab="probability", sub="prob=0.7")
plot.binom( size=1, prob=0.7, col="black", epsilon=0.0, connection=TRUE )
plot.binom( size=3, prob=0.7, col="red", epsilon=0.1, connection=TRUE )
plot.binom( size=5, prob=0.7, col="green", epsilon=0.2, connection=TRUE )
plot.binom( size=10, prob=0.7, col="blue", epsilon=0.3, connection=TRUE )
plot.binom( size=20, prob=0.7, col="purple", epsilon=0.4, connection=TRUE )
legend(12, 0.6, lty=1, col=c("black","red","green","blue","purple"),
legend=c("size=1","size=3","size=5","size=10","size=20"))
lines.binom.12( size=1, prob=0.7, ylim=c(0, 0.7), delta=0.1, col="blue", lwd=2, lty=3)
lines.binom.12( size=3, prob=0.7, ylim=c(0-0.01, 0.7-0.01), delta=0.1, col="red", lwd=2, lty=3)
lines.binom.12( size=5, prob=0.7, ylim=c(0-0.02, 0.7-0.02), delta=0.1, col="green", lwd=2, lty=3)
lines.binom.12( size=10, prob=0.7, ylim=c(0-0.03, 0.7-0.03), delta=0.1, col="blue", lwd=2, lty=3)
lines.binom.12( size=20, prob=0.7, ylim=c(0-0.04, 0.7-0.04), delta=0.1, col="purple", lwd=2, lty=3)
dev.off()
# Cumulative probability
postscript("binomial-distribution-2-0.7.eps", width=8, height=4)
plot(c(0,2), c(0,1.0), type="n", xlab="k", ylab="probability", sub="prob=0.7, size=2")
plot.binom( size=2, prob=0.7, col="purple", epsilon=0, connection=FALSE,
cumulative.prob=TRUE )
dev.off()
postscript("binomial-distribution-2-0.5.eps", width=8, height=4)
plot(c(0,2), c(0,1.0), type="n", xlab="k", ylab="probability", sub="prob=0.5, size=2")
plot.binom( size=2, prob=0.5, col="purple", epsilon=0, connection=FALSE,
cumulative.prob=TRUE )
lines.binom.12( size=2, prob=0.5, ylim=c(0-0.04, 0.7-0.04), delta=0.1, col="purple", lwd=2, lty=3)
dev.off()
postscript("binomial-distribution-2-0.3.eps", width=8, height=4)
plot(c(0,2), c(0,1.0), type="n", xlab="k", ylab="probability", sub="prob=0.3, size=2")
plot.binom( size=2, prob=0.3, col="purple", epsilon=0, connection=FALSE,
cumulative.prob=TRUE )
lines.binom.12( size=2, prob=0.3, ylim=c(0-0.04, 0.7-0.04), delta=0.1, col="purple", lwd=2, lty=3)
dev.off()
postscript("binomial-distribution-20-0.7.eps", width=8, height=4)
plot(c(0,20), c(0,1.0), type="n", xlab="k", ylab="probability", sub="prob=0.7, size=20")
plot.binom( size=20, prob=0.7, col="purple", epsilon=0.4, connection=FALSE,
cumulative.prob=TRUE )
lines.binom.12( size=2, prob=0.7, ylim=c(0-0.04, 0.7-0.04), delta=0.1, col="purple", lwd=2, lty=3)
dev.off()
postscript("binomial-distribution-20-0.5.eps", width=8, height=4)
plot(c(0,20), c(0,1.0), type="n", xlab="k", ylab="probability", sub="prob=0.5, size=20")
plot.binom( size=20, prob=0.5, col="purple", epsilon=0.4, connection=FALSE,
cumulative.prob=TRUE )
lines.binom.12( size=20, prob=0.5, ylim=c(0-0.04, 0.7-0.04), delta=0.1, col="purple", lwd=2, lty=3)
dev.off()
postscript("binomial-distribution-20-0.3.eps", width=8, height=4)
plot(c(0,20), c(0,1.0), type="n", xlab="k", ylab="probability", sub="prob=0.3, size=20")
plot.binom( size=20, prob=0.3, col="purple", epsilon=0.4, connection=FALSE,
cumulative.prob=TRUE )
lines.binom.12( size=20, prob=0.3, ylim=c(0-0.04, 0.7-0.04), delta=0.1, col="purple", lwd=2, lty=3)
dev.off()
postscript("binomial-distribution-20-0.3-mean-stddev.eps", width=8, height=4)
plot(c(0,20), c(0,1.0), type="n", xlab="k", ylab="probability", sub="prob=0.3, size=20")
plot.binom( size=20, prob=0.3, col="purple", epsilon=0.4, connection=FALSE,
cumulative.prob=TRUE )
lines.binom.12( size=20, prob=0.3, ylim=c(0-0.04, 0.7-0.04), delta=0.1, col="purple", lwd=2, lty=3)
dev.off()
## Exponential distribution
plot.exp <- function( rate=1, xlim=c(0, 20), tics=200, col="black", lty=1, col.cprob="black", lty.cprob=2, \
cumulative.prob=FALSE ) {
x <- c(0:tics)/tics * (xlim[2]-xlim[1]) + xlim[1]
dexp.func <- dexp(x, rate=rate, log=FALSE)
pexp.func <- pexp(x, rate=rate, lower.tail=TRUE, log.p=FALSE)
lines(x, dexp.func, col=col, lty=lty)
lines(x, pexp.func, col=col.cprob, lty=lty.cprob)
# print(x)
# print(dexp.func)
}
## Mean and standard error
lines.exp.12 <- function( rate=1, delta=0, epsilon=0, lty=1, lwd=1, col="black", ylim=c(0,1)) {
lines( c(1/rate, 1/rate), c(ylim[1]+delta, ylim[2]-delta), lty=lty, lwd=lwd, col=col)
lines( c(1/rate-sqrt(1/rate/rate), 1/rate+sqrt(1/rate/rate)),
c(mean(ylim), mean(ylim)), lty=lty, lwd=lwd, col=col)
}
# rate=c(0.25, 0.5, 1, 2, 4)
postscript("exponential-distribution.eps", width=8, height=4)
plot(c(0,5), c(0,1.2), type="n", xlab="x", ylab="density")
plot.exp(rate=0.25, xlim=c(0,5), tics=500, col="blue")
plot.exp(rate=0.5, xlim=c(0,5), tics=500, col="purple")
plot.exp(rate=1, xlim=c(0,5), tics=500, col="black")
plot.exp(rate=2, xlim=c(0,5), tics=500, col="red")
plot.exp(rate=4, xlim=c(0,5), tics=500, col="orange")
legend(3,0.9, lty=1, col=c("blue","purple","black","red","orange"),
legend=c("rate=1/4","rate=1/2","rate=1","rate=2","rate=4"))
lines.exp.12(rate=0.25, delta=0.2, ylim=c(0-0.08,1-0.08), lty=3, lwd=2, col="purple")
lines.exp.12(rate=0.5, delta=0.2, ylim=c(0-0.06,1-0.06), lty=3, lwd=2, col="blue")
lines.exp.12(rate=1, delta=0.2, ylim=c(0-0.04,1-0.04), lty=3, lwd=2, col="black")
lines.exp.12(rate=2, delta=0.2, ylim=c(0-0.02,1-0.02), lty=3, lwd=2, col="red")
lines.exp.12(rate=4, delta=0.2, ylim=c(0 ,1 ), lty=3, lwd=2, col="orange")
dev.off()
## Step function approximation
plot.exp.approx <- function( rate=1, xlim=c(0, 20), tics=200, col="black" ) {
x <- c(0:tics)/tics * (xlim[2]-xlim[1]) + xlim[1]
epsilon <- 1/tics * (xlim[2]-xlim[1]) / 2
dexp.func.mid <- dexp(x+epsilon, rate=rate, log=FALSE)
for ( i in c(1:tics) ) {
lines(c(x[i], x[i], x[i+1], x[i+1]), c(0, dexp.func.mid[i], dexp.func.mid[i], 0), col=col)
}
}
postscript("exponential-distribution-1.eps", width=8, height=4)
plot(c(0,5), c(0, 1.1), type="n", xlab="x", ylab="density", sub="Exp(1)")
plot.exp(rate=1, xlim=c(0,5), tics=500, col="black", lty.cprob=2, col.cprob="red", cumulative.prob=TRUE)
plot.exp.approx(rate=1, xlim=c(0,5), tics=10, col="blue")
legend(2.5, 0.6,
lty=c(1,1,2),
col=c("black", "blue", "red"),
legend=c("Density", "Step approx of density", "Cumulative probability"))
dev.off()
postscript("exponential-distribution-1-mean-stddev.eps", width=8, height=4)
plot(c(0,5), c(0, 1.1), type="n", xlab="x", ylab="density", sub="Exp(1)")
plot.exp(rate=1, xlim=c(0,5), tics=500, col="black", lty.cprob=2, col.cprob="red", cumulative.prob=TRUE)
plot.exp.approx(rate=1, xlim=c(0,5), tics=10, col="blue")
legend(2.5, 0.6,
lty=c(1,1,2),
col=c("black", "blue", "red"),
legend=c("Density", "Step approx of density", "Cumulative probability"))
lines.exp.12(rate=1, ylim=c(0.6,0.8), lty=3, lwd=2, col="black")
dev.off()